-
Innovation vs invention
Une innovation c’est typiquement quelque chose de nouveau et d’utile. Une innovation c’est l’incarnation, la combinaison, ou la synthèse de connaissances de produits, processus ou services originaux, pertinents et à valeur ajoutée.
Une invention c’est la première manifestation d’une idée pour un nouveau produit, ou processus, alors que l’innovation est la première tentative de la réaliser en pratique. Toute innovation commence avec des idées créatives. L’innovation c’est l’implantation réussie de ces idées créatives à l’intérieur d’une organisation. De ce point de vue la créativité des individus et des équipes est le point de départ de l’innovation: la première est la condition nécessaire, mais non suffisante de la deuxième. Bref, une innovation c’est une invention qui est mise en œuvre et commercialisée.
L’innovation est l’élément vital de toute organisation. Sans elle, non seulement il n’y a pas de croissance, il y a mort lente.
Innovation incrémentale vs radicale
Une innovation incrémentale consiste en de petites améliorations successives, faisant appel à des techniques de résolution de problème et à une créativité limitée; c’est une forme dominante dans les organisations établies et qui vise souvent à éviter la ‘’commoditisation’’ des produits et services offerts.
L’innovation technologique apporte des ‘’sauts quantiques’’ de performance, ou d’importants changements architecturaux. Elle a recours à des savoirs profonds et spécialisés. La propriété intellectuelle est souvent en jeu.
L’innovation de modèle d’affaires exerce un important levier, basé sur de nouvelles façons de faire des affaires ‘’ hors de la boîte’’, à partir de technologies existantes ou légèrement modifiées. Elle se base sur une compréhension profonde des dynamiques de marché et concurrentielles.
L’innovation radicale combine les deux en ce qu’on appelle un « game changer », i.e. quelque chose qui change fondamentalement les règles du jeu dans un espace de marché donné, ou réinventé.

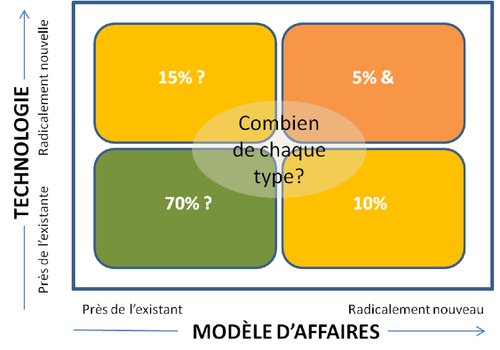
L’une des importantes décisions stratégiques à prendre en matière d’innovation c’est l’équilibre à viser entre les quatre types. Il n’y a pas de réponse unique. Tout dépend des conditions de chaque entreprise, de ses ressources, de son environnement concurrentiel, de son profil de risque, etc. Décider de sa stratégie d’innovation c’est décider de l’équilibre recherché entre divers leviers:
» capture de valeur existante vs créativité;
» innovation incrémentale vs radicale;
» technologie vs modèle d’affaires;
» innovation interne vs externe.
Processus et systèmes
Une bonne gestion de l’innovation comprend des processus et des systèmes bien établis, s’appuyant sur une vision claire, une culture favorable et des équipes internes et externes, préférablement dédiées. « Comment vous innovez dicte ce que vous innovez ».
L’un des processus les plus connu est la gestion du portefeuille d’innovation. C’est un processus dynamique de décision où la liste des projets actifs, nouveaux produits et de R&D, est constamment révisée. Chaque projet est évalué, choisi, mis en priorité. Les projets peuvent être accélérés, terminés, réduits en priorité, alors que les ressources sont allouées et réallouées. C’est un processus caractérisé par l’incertitude, de l’information en constante évolutions, des opportunités dynamiques, des buts multiples, des considérations stratégiques, des interdépendances entre les projets et des décideurs nombreux.

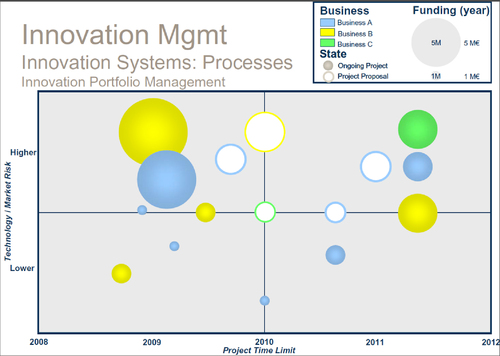
Au final on mesurera la performance d’innovation selon les critères suivants:
» Les ressources utilisées, leur motivation, leurs outils, etc.;
» Les processus utilisés: la qualité d’exécution, la qualité du portefeuille, le suivi;
» Les extrants: le nombre de nouveaux produits, services et procédés, le balisage avec la concurrence;
» Les résultats: croissance, profits, etc.
BON ÉTÉ

 1 commentaire
1 commentaire
-
Innovation de rupture
Le terme de “technologie de rupture” (disruptive technology) a été introduit en 1997, par Clayton M. Christensen dans son livre The Innovator's Dilemma. Par la suite il utilisera le terme plus générique “d’innovation de rupture”, considérant que peu de technologies sont intrinsèquement de rupture ou de continuité; ce n’est pas tant la technologie elle-même, que son utilisation stratégique, qui a un effet de rupture.
Par opposition, les technologies de continuité, ou d’amélioration continue, ne créent pas de nouveaux marchés : elle procèdent par améliorations et incréments graduels successifs des performances de la technologie actuelle. Les technologies de continuité peuvent être discontinues (transformationnelles) ou continues (évolutives). Par exemple l'automobile était, en premier, une technologie de transport transformationnelle et non pas une technologie de rupture, car les automobiles des débuts étaient des produits de luxes très chers, qui ne remplaçaient pas les véhicules tractés par des chevaux. Jusqu'à l'apparition en 1908 de la Ford T, une voiture à bas prix, produite en masse qui, elle, a été une technologie de rupture, car elle a réellement transformé le marché et les modes de transport. On peut penser à plein d’autres exemples de technologies de rupture (voir le tableau).

Une longue immunité
Le modèle d’affaires de la consultation, en particulier en management, n’a guère changé depuis cent ans. Il consiste toujours à envoyer, dans des organisations clientes, des ressources futées, venant de l’extérieur de celle-ci, pour une période de temps limitée, afin de trouver des réponses à leur problèmes les plus difficiles. Plusieurs consultants s’esclaffent de rire à la suggestion que ce modèle puisse un jour être “rupturé”; les clients feront toujours face à de nouveaux défis, après tout. Deux facteurs ont historiquement immunisé le secteur contre la rupture de son modèle d’affaires: son opacité et son agilité.
Le conseil est une industrie largement « opaque » où les solutions (les recommandations) sont créées dans une boîte noire (l’équipe de consultants en circuit fermé). En plus, il est très difficile pour le client d’évaluer en amont la performance probable d’une firme, puisque, généralement, il engage une firme pour des expertises et des compétences qu’il ne possède pas. Et ce n’est pas mieux en aval, puisque de très nombreux facteurs externes (qualité d’implantation, changement de direction, passage du temps, etc.) influenceront les conséquences des recommandations du consultant. Un mécanisme critique de rupture est donc désamorcé. Les clients doivent se rabattre sur des facteurs substituts, tels que la réputation, la marque, la formation académique, l’éloquence et le comportement — ce qui donne toujours un avantage aux firmes en place. Même le taux horaire devient une procuration, qui supporte les fortes primes chargées par les plus grandes firmes. Selon Christensen, dans les secteurs opaques les nouveaux concurrents tendent à émuler les firmes en place plutôt qu’à introduire des approches de rupture.
L’agilité des grandes firmes, quant à elle, se manifeste dans leur habilité, maintes fois démontrée, à passer en douceur d’une ”grande idée” à une autre, ce qui leur permet de faire face de façon flexible à toutes menaces de rupture. Pensons à la rapidité avec laquelle McKinsey et d’autres firmes ont répondu lorsque BCG a vu sa réputation croitre avec sa fameuse matrice stratégique. De plus le principal actif étant le capital humain et les investissements fixes étant minimaux, les firmes peuvent changer rapidement.
Mais ces deux avantages pourraient bientôt disparaitre.
La démocratisation du savoir
La transformation en cours du secteur conseil n’est pas une première. Les firmes de conseils légaux ont déjà commencé à la vivre (voir l’article en référence) et ils ont été largement surpris par la vitesse du changement. Par exemple, une enquête de 2009, auprès des associés directeurs et présidents de conseil de grandes firmes de droit américaines, relevait que seulement 42% d’entre eux entrevoyait une concurrence accrue sur les prix dans le futur; en 2012 ce nombre avait grimpé à 92%.
Kennedy Research estime le taux de rotation, dans les grandes firmes de conseil, à 18-20% par année. Plusieurs entreprises clientes engagent aujourd’hui d’anciens consultants, ce qui contribue à leur sophistication accrue comme acheteurs de services conseil. Typiquement ils deviennent des donneurs d’ordre plus exigeants, qui tendent à réduire l’envergure des mandats (et leur coût), à être plus actifs dans la sélection et la gestion des ressources assignées à ces mandats, et à faire plus de travaux eux-mêmes à l’interne.
Cette sophistication accrue conduit aussi les clients à désagréger les mandats, réduisant leur dépendance envers les fournisseurs de « solutions intégrées ». La dynamique concurrentielle se déplace, de ces firmes intégrées, vers des fournisseurs d’offres modulaires spécialisés. Un déplacement qui se produit lorsque des clients réalisent qu’ils paient trop pour des éléments qui ont peu de valeur pour eux et qu’ils veulent plus de contrôle.
En parallèle on voit aussi apparaitre des firmes alternatives de services professionnels, comme Eden McCallum et Business Talent Group (BTG) aux États-Unis. Ces firmes assemblent des équipes « lean » de consultants indépendants (souvent des gradués intermédiaires et seniors de grandes firmes), et ce, pour une fraction du coût des firmes traditionnelles (parce qu’elles ne supportent pas les coûts de temps non facturable, les loyers de centre-ville, la formation, etc.). Ils utilisent des approches et méthodologies éprouvées, répandues et publiques, plutôt que de développer des approches propriétaires. Les équipes comprennent souvent du personnel plus senior et la gestion du mandat est largement faite par le client.
Une autre tendance est l’apparition du « asset-based consulting,”; McKinsey Solutions en est un exemple. Cette tendance comprend le packaging d’idées, de processus, de cadres d’analyse et d’autres propriétés intellectuelles optimisées pour une livraison optimale par des moyens numériques. Le degré d’intervention humaine et de personnalisation varie, mais est généralement moindre que dans un mandat traditionnel; le coût est donc moindre et plus étalé dans le temps, via un frais de souscription, ou un frais de licence.
votre commentaire
-
Quelle est la part du hasard dans les grandes décisions?
Bill Gates est brillant, il a reçu une excellente éducation et, selon Malcolm Gladwell, l’auteur de Outliers, il a consacré dès un jeune âge plus de 10,000 heures à maitriser la programmation d’ordinateurs .
Mais le succès de Bill Gates dépend, en plus de son talent et de ses efforts, de son incroyable chance comme négociateur. Il a gagné à la roulette de la chance à trois reprises et ce, à un moment clé. Tôt dans sa carrière, il a fait une importante erreur; n’eut été du fait que d’autres personnes en ont fait de plus grosses, nous n’aurions peut-être jamais entendu parler de lui.
En 1980, avec quelques collègues, Gates a une petite firme informatique à Seattle et est approché par IBM pour développer le système d’opération (OS) des nouveaux ordinateurs personnels qu’ils s’apprêtent à lancer. N’ayant jamais développé d’OS, il refuse (!) et leur recommande plutôt les services de Gary Kildall chez Digital Research. Premier coup de chance, les négociations entre Digital et IBM tournent mal: Digital ne veut pas signer d’entente de confidentialité et exige des royautés de 20%, plutôt que le forfait offert de 250K$. IBM revient alors discuter avec Gates. Mais ce n’est pas tout! IBM et Gates savent que Seattle Computer Products (SCP) a déjà développé un OS (appelé QDOS). Gates, avec le support secret d’IBM, en fait l’acquisition à bas coût. SCP n’a jamais été au courant du rôle d’IBM et on peut penser qu’ils auraient pu demander beaucoup plus cher. Après quelques petits ajustements, Microsoft lançe DOS. En apparence, le géant IBM s’est négocié une bonne entente: une petite royauté sur chaque copie vendue (ils se sont possiblement ouverts à l’idée d’une royauté après l’échec avec Digital). Cependant, l’entente est non exclusive et Gates demeure le propriétaire de DOS! Si IBM avait insisté sur l’exclusivité, Gates l’aurait sûrement concédée. Microsoft aurait possiblement connu bien du succès quand même, mais jamais rien d’aussi spectaculaire.
Il en va de même pour toute décision importante.
La chaîne d’événements qui vous mène à un point de décision est façonnée par la chance, bonne ou mauvaise. De tout temps, philosophes, théoriciens des sciences politiques et stratèges ont reconnu le rôle important que joue le hasard. Même Nicolo Machiavelli a affirmé: "Je crois qu’il est probablement vrai que la fortune est l’arbitre de la moitié des choses que nous faisons, laissant l’autre moitié sous notre contrôle."
En quoi reconnaitre ce fait peut-il nous aider dans nos décisions d’affaires? Reconnaitre le rôle du hasard peut nous amener à faire deux choses différemment. Premièrement, nous pouvons approcher la prise de décision autrement et cesser de trouver brillantes chacune de nos décisions qui, rétrospectivement, se sont avérées bonnes. Deuxièmement, nous pouvons nous concentrer sur d’autres habilités importantes dans la prise de décision, comme, par exemple, la capacité et la flexibilité à exploiter des changements de chance, plutôt que d’essayer de prédire d’avance comment les choses vont tourner.
Et le contexte, joue-t-il aussi un rôle?
La directrice des services alimentaires d’une commission scolaire se demandait si la façon dont la nourriture est présentée a une influence sur les choix alimentaires des élèves. Pour tester cette hypothèse, elle donna des instructions précises aux directeurs de plusieurs cafétérias d’école quant à la façon d’organiser l’offre de nourriture. Ainsi, dans certaines écoles on présenta les desserts en première ligne et ailleurs en bout de piste ou encore dans une rangée séparée. La place de divers aliments était également différenciée d’une école à l’autre: dans certaines, on présenta les frites à hauteur des yeux, alors qu’ailleurs ont y plaçait les légumes; etc.
Elle constata qu’avec une simple réorganisation de la cafétéria elle pouvait augmenter ou diminuer la consommation de certains aliments de 25%. Les élèves, tout comme les adultes, sont fortement influencés par de petits changements dans leur contexte, et cette influence peut être exercée pour le bien comme pour le mal.
Cette directrice a donc le pouvoir de faire monter la consommation d’aliments santé et de faire baisser la consommation de camelote. Mais un dilemme se pose: comment exercer ce pouvoir? Parmi diverses options on pourrait mentionner:
1. Arranger la nourriture pour le plus grand bien des élèves.
2. Placer la nourriture au hasard.
3. Essayer de placer la nourriture pour favoriser les aliments que les élèves choisiraient eux-mêmes.
4. Maximiser la vente des aliments venant des fournisseurs qui lui offrent un pot-de-vin.
5. Maximiser les profits des cafétérias.
L’option1 est attrayante, quoiqu’un peu intrusive, pour ne pas dire paternaliste. L’option 2 peut sembler équitable et neutre, mais dans certaines écoles les élèves auraient alors une diète moins santé. L’option 3 pourrait être une bonne approche de non-ingérence, mais ne répond pas à la question de déterminer les vrais préférences des élèves, puisque celles-ci seront influencées par la façon de leur présenter un choix. L’option 4 n’attirera qu’une directrice corrompue, et l’option 5 n’est valide que si l’on présuppose que les meilleures cafétérias sont aussi les plus profitables, même au détriment de la santé des élèves. Le point à retenir est que, peu importe la décision (ou le refus de décider) de la directrice, il y aura nécessairement un arrangement résultant et celui-ci affectera les choix faits par les élèves.
La directrice de cet exemple est ce que Sunstein et Cass (prix Nobel d’économie) appellent une architecte des choix, i.e. une personne responsable d’organiser le contexte dans lequel des personnes prennent leurs décisions. Plusieurs personnes, même sans s’en rendre compte, sont des architectes des choix: la personne qui conçoit un bulletin de vote, le docteur qui présente des alternatives de traitement, un vendeur qui présente diverses options, etc.
Tout architecte sait qu’il n’y a pas de design « neutre ». Au-delà des spécifications de départ (par exemple 150 bureaux, 8 salles de réunions, etc. pour un nouveau building) et des contraintes (légales, esthétiques, pratiques), l’architecte devra prendre une multitude de petites décisions « arbitraires » (par ex.: où placer les toilettes) qui auront une influence profonde sur les interactions des gens dans ce building. Une simple visite aux toilettes devient une occasion, bonne ou mauvaise, de rencontrer des collègues.
Un bon building n’est pas seulement attrayant; il « fonctionne ».
Plein de petits détails, en apparence insignifiants, peuvent avoir un impact important sur le comportement des gens. Une bonne règle du pouce est de présumer que tout importe.
Parfois, le pouvoir de ces détails vient simplement du fait qu’ils concentrent l’attention sur une direction particulière. À l’aéroport Schiphol d’Amsterdam, les autorités ont peint l’image d’une mouche noire au centre des urinoirs pour limiter les « dégâts ». En effet, Il semblerait que les hommes en général ne porte pas toujours une grande attention à la tâche dans ce contexte, mais en leur donnant une cible, la précision de leur visée augmente. Selon le responsable, cette initiative a réduit les débordements de plus de 80%!
L’idée que tout importe peut être à la fois habilitante et paralysante. Il n’y a jamais de design parfait mais on peut toujours faire des choix bénéfiques. Il faut juste se rappeler que la façon de présenter les options influencera la décision qui sera prise.
votre commentaire
-
Dans l’édition précédente, nous avons constaté l’existence de « l’effet de déclin » en science. Nous continuons notre recherche d’une explication à ce phénomène qui constitue une préoccupation très sensible pour les scientifiques et la validité de la méthode scientifique.
Un effet de mode?
Leigh Simmons, un biologiste à l’Université Western Australia, a rencontré le phénomène au milieu des années 90, en étudiant la relation entre l’ asymétrie et l’attrait sexuel chez certains oiseaux. Les premières études avaient démontré une relation très robuste entre des deux facteurs. Il décida de conduire ses propres études; malheureusement, il n’arriva pas à reproduire l’effet prédit. “Mais le pire”, dit-il, “c’est que lorsque j’ai soumis ces résultats nuls, j’ai eu des difficultés à les faire publier. Les journaux [scientifiques] voulaient seulement des données qui confirmaient [la théorie]. C’était une idée trop excitante pour être réfutée, du moins à l’époque.”
Pour lui, la montée rapide et le lent déclin de la théorie de l’asymétrie est un exemple marquant d’un paradigme scientifique, une de ces modes intellectuelles qui guide et contraint la recherche tout à la fois: une fois qu’un nouveau paradigme est proposé, le processus de revue par les pairs (un processus traditionnel d’assurance de la méthode scientifique) est biaisé envers les résultats positifs qui le confirment. Ensuite, après quelques années, la motivation académique change: le paradigme étant bien établi, les résultats les plus soulignés sont maintenant ceux qui réfutent la théorie.
Dans la même veine, Jennions argumente que l’effet de déclin est un produit du biais de publication, i.e. la tendance des scientifiques et des journaux scientifiques de préférer les résultats positifs aux résultats nuls (i.e. quand on ne trouve aucune relation ou effet). Ce biais a été noté pour la première fois en 1959 par le statisticien Theodore Sterling. Il avait alors constaté que 97% de toutes les études publiées en psychologie contenant des données statistiquement significatives trouvaient l’effet recherché. Un résultat « significatif » est défini comme toute donnée qui serait due au hasard moins de 95% du temps. Ce test omniprésent a été inventé en 1922 par le mathématicien anglais Ronald Fisher; il avait choisi cette frontière de 5% de façon quelque peu arbitraire, parce qu’elle facilitait les calculs alors faits à la main ou à la règle à calcul. Sterling conclut que si 97% des études en psychologie prouvaient leurs hypothèses, les psychologues étaient soit extraordinairement chanceux, ou alors ils ne publiaient que les résultats des expériences réussies. C’est un phénomène qu’on observe aujourd’hui dans les essais cliniques, les compagnies pharmaceutiques étant peu intéressées à publier des résultats non favorables. Il est clair que ce biais produit des distorsions majeures dans d’autres domaines aussi.
Un aveuglement (in)volontaire?
Toutefois, ces biais ne fournissent pas une explication complète. Ils n’expliquent pas la prévalence initiale de résultats positifs dans des études qui ne sont pas publiées, ni l’incapacité à les reproduire par la suite.
Richard Palmer, un biologiste à l’Université d’Alberta, croit qu’un problème important est la déclaration sélective des résultats — i.e. les données que les scientifiques choisissent de documenter. Sa preuve la plus convaincante se base sur un outil statistique appelé un graphique entonnoir. Lorsque plusieurs études sont réalisées sur un sujet, les données devraient suivre un patron: les études sur de larges échantillons devraient se regrouper autour d’une valeur commune (le vrai résultat), alors que celles conduites sur de petits échantillons devraient être plus éparpillées, parce que sujettes à une plus grande erreur d’échantillonnage. Cela donne au graphique une forme caractéristique qui ressemble à un entonnoir.
L’analyse de Palmer sur certaines études démontre que la distribution des résultats de petits échantillons n’est pas du tout aléatoire, mais plutôt fortement biaisée du côté des résultats positifs. “On ne peut échapper à la conclusion troublante que certaines - peut-être plusieurs - des généralisations auxquelles nous sommes attachés sont, au mieux, exagérées dans leur signification et, au pire, une illusion collective nourrie par de fortes croyances a priori et souvent répétées. »
L’action même de mesurer est vulnérable à toutes sortes de biais de perception. Ce n’est pas un commentaire cynique, juste la façon dont l’être humain fonctionne. Par exemple, notre culture peut influencer nos résultats. Entre 1966 et 1995, il y a eu 47 études sur l’acupuncture en Chine, à Taiwan et au Japon, et toutes ont conclu que l’acupuncture était un traitement efficace. Dans la même période, il y a eu 94 essais cliniques de l’acupuncture aux États-Unis, en Suède et au Royaume-Uni, et seulement 56% d’entre elles ont trouvé des effets thérapeutiques bénéfiques.
Ces « exagérations » sont probablement la cause principale de l’effet de déclin. En 2005, une étude publiée dans le Journal of the American Medical Association a examiné les 49 études cliniques les plus citées dans trois journaux médicaux majeurs. 45 d’entre elles rapportaient des résultats positifs, indiquant que l’intervention testée était efficace. Parce que ces études étaient largement des essais aléatoires contrôlés (une règle d’or de la preuve médicale), ils ont eu un impact important sur la pratique clinique et ont résulté dans la diffusion de traitements tels que la thérapie de remplacement hormonal chez les femmes ménopausées, ou encore la prise quotidienne d’aspirine à faible dose pour prévenir les attaques cardiaques. Cependant, l’analyse de leurs données a révélé un point inquiétant: des 34 prétentions assujetties à des études ultérieures, pour répliquer leurs résultats, 41% ont vu ceux-ci contredits ou la taille des leurs effets largement réduits.
Le principal problème est que trop de chercheurs se lancent dans ce que John Ioannidis, un épidémiologiste à l’Université Stanford, appelle la « poursuite de la signification», i.e. comment trouver des façons d’interpréter les données pour qu’elles atteignent le 95% du test de Fisher. “Les scientifiques sont tellement anxieux de passer ce test magique qu’ils commencent à jouer avec les chiffres, essayant de trouver quoi que ce soit qui semble d’intérêt”, avance Ioannidis.
À la source du problème de déclaration sélective se trouve un défaut cognitif fondamental: nous aimons avoir raison et détestons avoir tort. On se sent bien quand on valide son hypothèse, encore plus quand on y trouve un intérêt financier, ou que notre carrière en dépend. C’est humain, après tout.
Un problème incontournable?
Bien que diverses approches, visant à une plus grande rigueur, existent pour réduire les dangers du biais de publication et de la déclaration sélective, elles n’élimineraient quand même pas l’effet de déclin. Cela est dû au fait que la recherche scientifique sera toujours ombragée par une force qui ne peut être contrôlée, mais seulement limitée: le pur hasard. En effet, le peu de recherche existante sur les dangers expérimentaux du hasard est peu encourageante.
À la fin des années 90, John Crabbe, un neuroscientifique de l’Oregon Health and Science University, a réalisé une étude pour démontrer comment des événements aléatoires inconnus pouvaient biaiser des expériences. Il a fait une série d’expériences sur des souris dans trois labos: Albany (New York), Edmonton (Alberta) et Portland (Oregon). Il a tenté de standardiser toutes les variables possibles: même souche de souris, souris expédiées du fournisseur le même jour, élevées dans les mêmes cages, en même nombre, avec la même sorte de paille, nourries et éclairées de la même façon, manipulées avec les mêmes gants, testées avec les mêmes appareils, etc. La prémisse était bien sûr que les trois labos obtiendraient les mêmes résultats. Eh bien non! Après leur avoir injecté de la cocaïne, les souris de Portland se sont déplacées de 600 cm de plus que la normale et celles d’Albany de 701 cm. Celles d’Edmonton? De 5000 cm.
Une implication dérangeante de cette étude est qu’un bon nombre de données scientifiques ne sont rien d’autre que du bruit.
En conclusion
Tout cela suggère que l’effet de déclin est en fait un déclin d’illusion. Bien que Karl Popper ait imaginé que la falsification d’une théorie puisse se produire qu’avec une seule expérience définitive — Galilée a réfuté la mécanique Aristotélicienne en un après-midi — le processus est beaucoup plus compliqué. Plusieurs théories scientifiques continuent à être considérées vraies, même après avoir échoué plusieurs tests expérimentaux. Cela a été observé dans de nombreux domaines; par exemple, on a vu disparaitre les bénéfices des antipsychotiques de deuxième génération, et s’affaiblir le ratio d’accouplement exhibé par les neutrons en désintégration (ce ratio semble avoir diminué de plus de dix déviations standards, entre 1969 et 2001). Même la loi de la gravité en arrache. Des physiciens effectuant des tests sur la gravité via des trous de forage dans le désert du Nevada ont observé un écart de 2.5% entre les prédictions théoriques et les données réelles. Malgré tout cela, les antipsychotiques de deuxième génération sont toujours prescrits et notre modèle du neutron n’a pas changé. La loi de la gravité demeure la même.
Ces « anomalies » démontrent l’instabilité de l’empirisme. Bien que plusieurs idées scientifiques génèrent des résultats conflictuels et voient la taille de leur effet réduire au fil du temps, elles continuent à être citées dans les livres de classe et à guider la pratique médicale standard. Pourquoi? Parce que ces idées semblent vraies. Parce qu’elles font du sens. Parce qu’on ne peut tolérer de les abandonner.
Et c’est pourquoi l’effet de déclin est tellement troublant. Pas parce cela révèle la faillibilité humaine de la science, dans laquelle des données sont manipulées et où les croyances façonnent les perceptions. Et pas, non plus, parce que cela révèle que plusieurs de nos théories les plus excitantes ne sont que des modes fugaces qui seront bientôt rejetées. L’effet de déclin est troublant parce qu’il nous rappelle à quel point il est difficile de prouver quoi que ce soit. On aime prétendre que nos expériences définissent la réalité pour nous. Mais, souvent, ce n’est pas le cas. Juste parce qu’une idée est vraie ne veut pas dire qu’elle peut être prouvée. Et juste parce qu’une idée peut être prouvée ne veut pas dire qu’elle est vraie. Une fois les essais terminés, nous devrons encore et toujours décider quoi croire.
Et vous, qu’en concluez-vous?
votre commentaire
-
Croiriez-vous que de nombreux résultats scientifiques, pourtant rigoureusement prouvés et acceptés par la communauté scientifique, s’effritent dans des études subséquentes (i.e. deviennent de moins en moins vrais)?
Qu’est-ce qui ne va pas avec la méthode scientifique?
Le 18 septembre 2007, des neuroscientifiques et dirigeants de grandes entreprises pharmaceutiques étaient réunis à Bruxelles pour une conférence sur un type de médicaments anti-psychotiques de deuxième génération, sur le marché depuis le début des années 90 (e.g. Abilify, Seroquel, Zyprexa). Ces médicaments avaient été testés dans le cadre de nombreux tests cliniques de grande taille, lesquels avaient tous démontré une réduction dramatique des symptômes psychiatriques des patients. Par conséquent, ces médicaments étaient devenus l’une des catégories les plus profitables et ayant la plus forte croissance de l’industrie.
Or, les résultats présentés à Bruxelles indiquaient clairement quelque chose d’étrange: l’effet thérapeutique de ces médicaments semblait décroitre de façon continue. Une étude récente montrait un effet moitié moindre que celui documenté dans les tests initiaux. Soudainement ces médicaments ne semblaient pas meilleurs que les plus anciens.
Avant que l’efficacité d’un médicament ne soit confirmée, celui-ci doit être testé et re-testé dans différents laboratoires, par différents chercheurs suivant le même protocole et qui publient leurs résultats. Ce test de reproductibilité est la fondation même de la méthode scientifque. C’est la façon qu’a la communauté scientifique de s’auto-discipliner. Bien que les chercheurs anticipent généralement les résultats qu’ils cherchent - ce qui pourrait les influencer - la reproductibilité est un mécanisme pour pallier à cette subjectivité.
Or, de plus en plus de résultats bien établis et confirmés à répétition semblent remis en question. C’est comme si nos faits perdaient de leur vérité: des énoncés, enchâssés depuis longtemps dans les manuels scolaires, sont soudainement improuvables!
Ce phénomène, qui n’a pas encore de nom, apparait dans une large variété de domaines scientifiques. Pour plusieurs scientifiques, cet effet est particulièrement troublant dans ses implications quant à la méthode scientifique. Si la reproductibilité est ce qui sépare la rigueur de la science du gargouillis de la pseudoscience, que doit-on faire de tous ces résultats, rigoureusement validés, qui ne peuvent plus être prouvés? Que doit-on croire?
L’effet de déclin
Jonathan Schooler, de l’université de Washington, a fait une importante découverte, vers la fin des années 80, à propos du langage et de la mémoire. Bien que l’on pense que le fait de décrire ses souvenirs aide à les améliorer, ses recherches ont démontré le contraire.
Étonnamment, dans de nombreuses situations, le fait de devoir décrire en mots nos observations et nos choix résulte en une moins bonne performance par la suite (par ex. reconnaitre des visages qu’on a vus sur des photos vs des visages qu’on a vus et dus décrire). Il a appelé ce phénomène « l’éclipsage verbal » (verbal overshadowing) et cette théorie est devenue immensément populaire.
Un problème rongeait cependant Schooler. Il avait de plus en plus de difficulté à reproduire ses propres conclusions. L’effet était toujours là, mais moins fort. Sa première tentative de réplication, en 1995, indiquait un effet 30% moindre qu’en 1990. L’année d’après, une autre étude montrait en effet réduit d’un 30% additionnel. « C’est comme si la nature me donnait ce résultat fameux et puis tentait de me le reprendre » dit-il. Il commença à appeler ce problème de l’habituation (par analogie au phénomène de réponse décroissante observée chez les individus qui s’habituent à des stimuli); c’est le « cosmos qui s’habitue à mes idées », disait-il à la blague.
Convaincu qu’il venait de trébucher sur un problème sérieux, il continua à l’investiguer et s’aperçut qu’une de ses premières manifestations avait été documentée dans les années 30 par Joseph Banks Rhine, un psychologue de Duke. Dans le cadre d’une étude sur la perception extrasensorielle, il demandait à des sujets de « percevoir » l’un des cinq symboles possibles au verso des cartes présentées. Sans surprise, les sujets réussissaient en moyenne 20% des fois, sauf un M. Zenmayer, dont le taux de réussite avoisinait 50%, avec de longues séries de succès (9). Une telle séquence a une probabilité de une sur deux millions et Zenmayer l’avait fait trois fois. Alors qu’il documentait ces résultats et commençait à croire à la perception extrasensorielle, Rhine s’aperçut que Zenmayer ne pouvait soudainement plus répéter sa performance. Au cours des deux années suivantes, il n’a jamais pu faire mieux que 20%. Ce phénomène s’est répété par la suite avec d’autres sujets: on observe une habilité hors norme suivie d’un rapide déclin par la suite, ce qu’il nomma « l’effet de déclin ».
Fasciné par ce scientifique qui semblait avoir un talent pour documenter des résultats qui se détériorent, Schooler décida d’en faire une imitation ironique. Il décida de tester le phénomène parapsychologique de la précognition. On montre à des personnes une série d’images et ce, tellement rapidement que les sujets ne peuvent identifier l’image dans la plupart des cas. Ensuite, on leur montre à nouveau la moitié des mêmes images choisies au hasard, mais plus lentement. Ce qu’on veut examiner c’est si les images observées après coup avaient plus de chance d’être parmi celles qui avaient été identifiées au premier tour. Est-ce que le deuxième visionnement pouvait avoir influencé le premier? Est-ce que l’effet pouvait devenir la cause?
Le ridicule de cette hypothèse était au coeur même de l’expérience de Schooler. Ce qu’il voulait vraiment tester c’était l’effet de déclin. Et, de fait, il a d’abord été renversé par le degré de précognition observé; mais plus il testait et plus la « taille de l’effet » (une mesure statistique standard) diminuait.
Des pistes d’explication
L’explication la plus probable est aussi la plus évidente: c’est un phénomène bien connu de régression vers la moyenne. Comme dans toute expérience, il se peut qu’un coup de chance se produise au début (en fait, plus un échantillon est petit et plus la probabilité que cela se produise est grande). Cependant, plus on répètera l’expérience et plus les effets « chanceux » initiaux disparaitront pour revenir vers la moyenne. L’effet de précognition n’a donc pas disparu - c’est simplement une illusion qui s’est effacée au fil du temps.
Malheureusement, cette explication ne suffit pas. Schooler a observé que plusieurs des cas où des résultats ont « décliné » concernaient des ensembles de données statistiquement solides, i.e. qui contenaient suffisamment de données pour éliminer tout effet significatif de régression vers la moyenne. « Ce sont des résultats qui passent tous les tests. Les chances qu’ils soient dus au hasard sont typiquement minuscules, du genre une chance sur un million. Cela signifie que l’effet de déclin n’aurait pratiquement jamais dû se produire. Mais il se produit tout le temps. Merde, ça m’est arrivé de nombreuses fois! »
L’ubiquité de l’effet de déclin semble défier les lois de la statistique. En 2001, Michael Jennions, un biologiste à l’Australian National University, a analysé les « tendances chronologiques » d’une grande variété de sujets en écologie et en biologie évolutive. Il a analysé des centaines de publications et 44 méta-analyses et a découvert un effet de déclin consistant dans le temps, plusieurs théories semblant pâlir jusqu’à en perdre leur pertinence. Même après avoir éliminé plusieurs autres facteurs possibles, Jennions a observé une diminution significative de la validité des hypothèses testées, parfois moins d’un an après leur publication initiale.
Suite au prochain numéro pour d’autres explications possibles— Bon automne!
votre commentaire









|
|
|
|